Last week I received the following error on my DR ESXi host:

The host in question is a Dell PowerEdge R710, and this indicated a hardware failure of some sort.
mpx.vmhba32:C0:T0:L0 is an 8GB SanDisk SD card containing the ESXi 5.5 boot partitions. With this gone, it meant the host would still live, but any changes wouldn’t be saved. It was also unlikely that the host would boot up again.
Sure enough this turned out to be the case. Three times out of four the server would hang at the BIOS. To remedy this I disconnected the SD card reader and ordered a replacement.
Unfortunately this turned out to be a red herring, as the new SD card reader failed to be recognised, as did the internal USB stick. After further testing, I decided it was the control panel (a daughterboard that the SD card reader, internal USB and console port plug into) that was faulty. After replacing that, the server booted normally into ESXi.
The total downtime was about ten days, which meant when the remote vCenter and vSphere Replication servers came back up there was a lot of data which needed to be replicated. This subsequently hammered my web connection, so much so that I couldn’t even bring up the vCenter Web Client to monitor how the replication was going.
To find out I needed to switch to the command line.
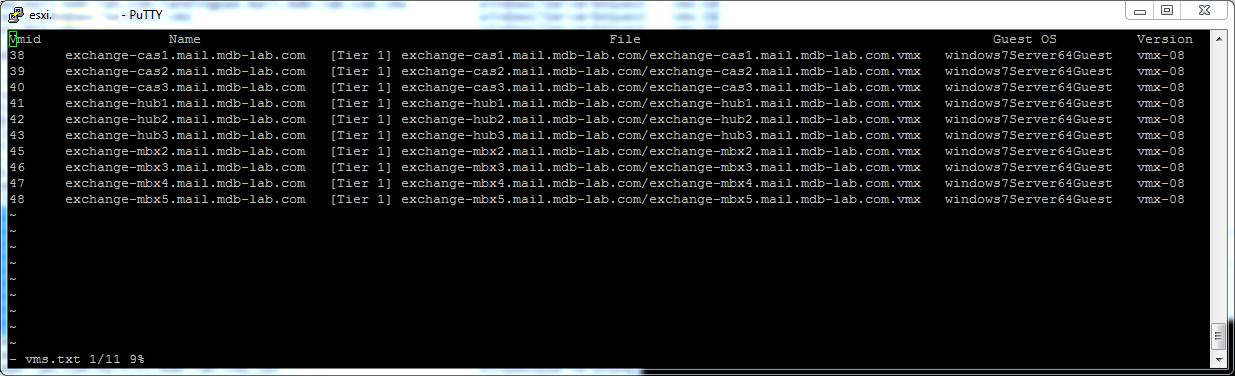
On the source host I used the following command to get the list of VMs and their associated VM IDs:
vim-cmd vmsvc/getallvms
This give an output similar to:

With each VM ID number, I then used the following command to get status of each replication:
vim-cmd hbrsvc/vmreplica.getState vmid
That told me exactly how much had replicated and how much was left to do. With a total of thirteen VMs to replicate, that was going to take a while!

The BusyBox shell on ESXi is quite limited, but a loop such as:
for i in `seq 38 43`; do vim-cmd hbrsvc/vmreplica.getState $i; done | grep DiskID
Gives me a basic overview on how my mail replications are going:

In the long-run this hasn’t caused too much of an issue, however it has made me think about moving my DR needs to vCloud Air…
52.370216
4.895168
 In the last Wednesday Tidbit I showed how to protect a VM using SRM and PowerCLI.
In the last Wednesday Tidbit I showed how to protect a VM using SRM and PowerCLI.